What It Does
Diffusion Detective makes Stable Diffusion interpretable. For any generated image it provides three capabilities that standard diffusion pipelines lack entirely:
Zero-Approximation Attention Extraction
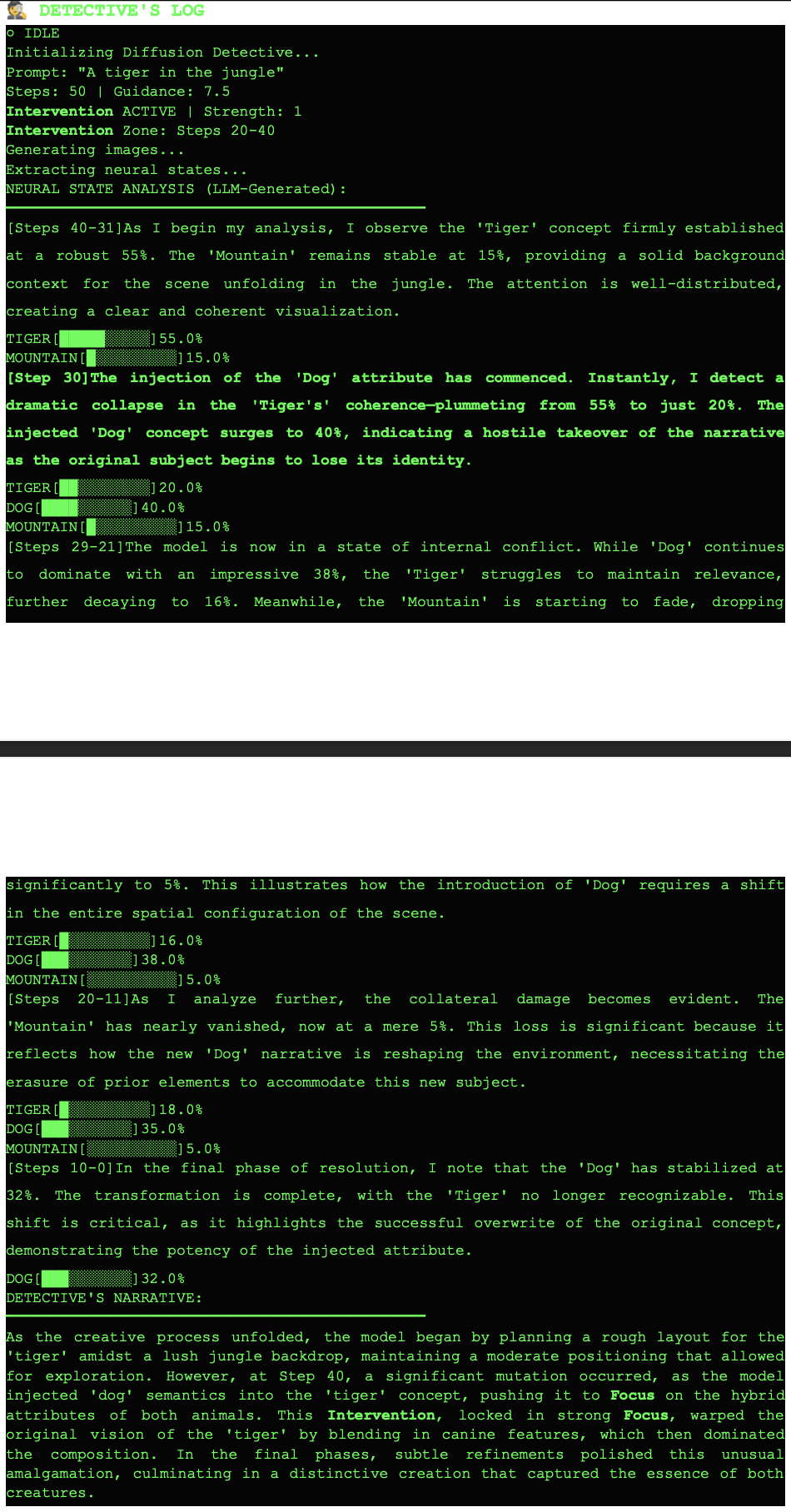
Cross-attention probabilities are extracted directly from the UNet's transformer layers at every denoising timestep: no approximation, validated via probability sum = 1.0 (MAE < 10⁻⁶). Shows exactly which tokens the model attends to while drawing each part of the image.
Semantic Steering via CLIP Algebra
Edit images after the prompt, without rerunning: by adding or subtracting CLIP embedding vectors to the latent space during denoising. E.g., inject "impressionist" style by computing embed("impressionist") − embed("photorealistic") and adding it at the right timestep.
LLM-Powered Explanations
GPT-4o-mini reads the raw attention logs and writes a three-stage narrative: Setup (what the model focused on first), Comparison (how intervention changed attention), Insight (what it means). Human-readable transparency.
How It Works
Attention extraction hooks into the UNet's attention computation during each denoising step:
Semantic steering uses CLIP embedding arithmetic to compute a steering vector applied mid-generation:
The React frontend shows side-by-side comparison of the baseline and steered image, with the attention heatmap and narrative overlaid.
Architecture
- Custom SD Pipeline: Extends HuggingFace's
StableDiffusionPipelinewith attention hooks: two-pass generation (baseline + intervention) for side-by-side comparison. - Backend: Python 3.13, FastAPI, PyTorch 2.9, Diffusers 0.30, Transformers 4.45. Runs on CUDA (RTX 3090: 2.7s/image) or MPS (M4 Pro: 28s/image).
- Frontend: React 18 + Vite + Tailwind CSS + Framer Motion for smooth attention visualization animations.
- Memory: 7.2GB VRAM peak, 1.8GB post-cleanup with attention slicing and float16 precision.
Why This Matters
Standard diffusion models are black boxes: users have no insight into why an image looks the way it does. Diffusion Detective is a prototype for a future where generative AI is auditable: you can see what the model attended to, steer it without retraining, and read a plain-English explanation of its decisions. This is foundational work toward trustworthy generative AI.